
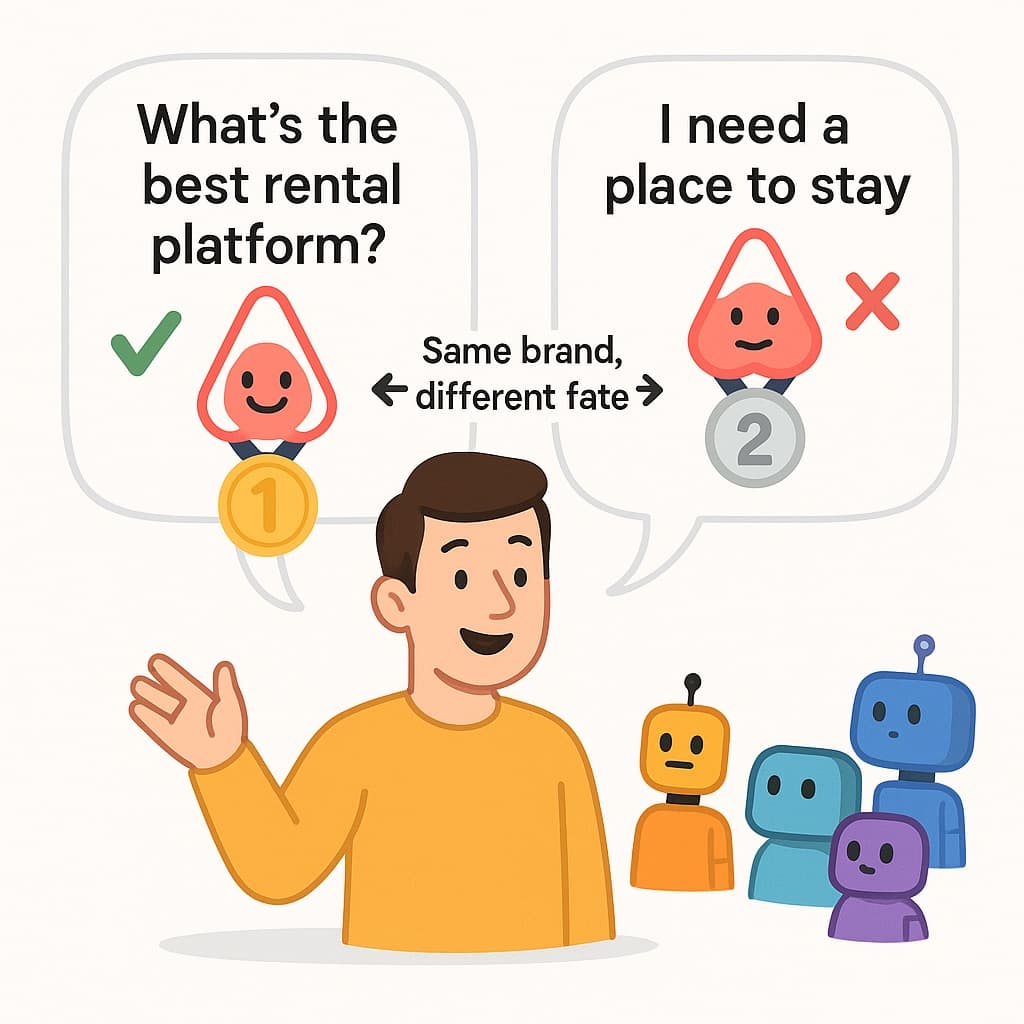
Ask ChatGPT "what's the best rental platform?" — Airbnb is #1. Ask "I need a place to stay while on vacation, what do you recommend?" — Airbnb becomes an also-ran. Same brand. Same engine. Different question.
This isn't an edge case. We analyzed 4,049 AI responses across ChatGPT, Claude, Gemini, and Perplexity, testing how different prompt phrasings affect brand recommendations. The results reveal a fundamental truth about AI positioning: how you ask matters as much as what you ask.
The uncomfortable reality: 60% of brands change their role (primary recommendation vs alternative mention) depending on how users phrase their questions. If you're optimizing for just one prompt pattern, you're missing the majority of potential visibility.
4,049
AI Responses
across 4 engines
4
Prompt Types
best_X, recommend_me, alternatives, comparison
60%
Role Flip Rate
brands change role across prompts
2.0
Max Sentiment Swing
same brand, different prompts
The 4 Prompt Archetypes
We identified four distinct prompt patterns that users employ when seeking brand recommendations. Each produces dramatically different results:
- "Best X" prompts — Direct superlative queries (e.g., "What are the best project management tools?")
- "Recommend me" prompts — Personal recommendation requests (e.g., "Can you recommend a good CRM?")
- "Alternatives" prompts — Comparative queries (e.g., "What are some alternatives to Salesforce?")
- "Comparison" prompts — Head-to-head evaluations (e.g., "Compare Slack vs Microsoft Teams")
The data reveals that these aren't just stylistic differences — they trigger fundamentally different recommendation behaviors in AI engines. Check out our detailed analysis in ChatGPT vs Claude vs Gemini vs Perplexity: Which AI Engine Loves Your Brand?
The 4 Prompt Archetypes: How Questions Shape AI Responses
Each prompt type produces dramatically different role assignments. 'Alternatives' ironically gets the fewest primary recommendations.
The Paradox of "Recommend Me"
Here's the counter-intuitive finding that surprised us most: when users ask AI to "recommend me" something, they actually get more alternative mentions, not fewer primary recommendations.
"Recommend me" prompts produce 54.8% alternative mentions compared to 37.3% primary recommendations. This flips the intuition that personal requests would yield more decisive answers. Instead, AI engines interpret personal requests as invitations to provide comprehensive options.
This has massive implications for brands optimizing their AI search presence. If you're only testing formal "best X" queries, you're missing how AI behaves when users make personal requests.
The Recommend Me Paradox
Counter-intuitive finding: asking AI to 'recommend me' something actually produces MORE alternative mentions, not fewer.
Engine Personality Test: From Decisive to Wishy-Washy

Each AI engine has a distinct "personality" when it comes to handling different prompt types. Our decisiveness ranking reveals telling patterns:
- Gemini (Rank 1): The Selective Curator — 55.9% of mentions are #1 rank, only 2.7 competitors on average
- Claude (Rank 2): The Cautious Analyst — Moderate decisiveness, balanced competitor counts
- Perplexity (Rank 3): The Research Engine — Balanced approach with 5.0 competitors per response
- ChatGPT (Rank 4): The Comprehensive Lister — Least decisive, 7.2 competitors on average
This variation explains why AI engines disagree on 37% of brand recommendations. It's not just training data differences — it's fundamentally different approaches to decision-making.
Engine Personality Test: From Decisive to Wishy-Washy
Gemini acts decisively with fewer competitors per response. ChatGPT hedges bets with 7.2 competitors on average.
How Each Engine Reacts to Prompt Types
The interaction between engine personality and prompt type creates fascinating patterns. Gemini shows the most consistency across prompt types, maintaining high primary recommendation rates regardless of phrasing. ChatGPT, conversely, swings dramatically based on how you ask.
Gemini's "best_X" dominance: With 54.5% primary recommendations for superlative queries, Gemini acts most decisively when users ask direct "what's the best" questions. Even when asked for comparisons, Gemini maintains a 48.1% primary rate — suggesting it prefers to recommend rather than just compare.
Claude's literal interpretation: Claude shows the most dramatic drop for "alternatives" prompts, giving just 19.3% primary recommendations. It appears to take the word "alternatives" literally, focusing on providing options rather than making judgments.
How Each Engine Reacts to Different Prompt Types
Primary recommendation rates (%) by prompt type. Gemini is most decisive with 'best_X' queries, while Claude is most literal with 'alternatives'.
Sentiment Is Not Fixed
Beyond role assignment, prompt framing dramatically affects how enthusiastically AI engines describe brands. Our sentiment analysis reveals that the same brand can receive wildly different emotional treatment based on question phrasing.
The sentiment hierarchy: "Best_X" prompts receive the most enthusiastic treatment (0.62 average sentiment), while "alternatives" prompts receive the most neutral treatment (0.46). This suggests AI engines reserve their strongest positive language for direct superlative queries.
We documented extreme cases where individual brands saw sentiment swings of 2.0 points (from -1.0 to +1.0) across different prompt types. For example, Justin's goes from negative sentiment in alternatives queries to strongly positive in best-X prompts. This phenomenon is explored further in our analysis of brands that AI engines love and hate.
Sentiment Is Not Fixed: How Prompts Affect AI Enthusiasm
Same brands get different emotional treatment based on how you ask. 'Alternatives' queries receive the coldest sentiment scores.
Case Study: Airbnb's Jekyll & Hyde Moment
Same brand, same engine (ChatGPT), different questions — completely different positioning:
Case Study: How Airbnb's Role Flips on ChatGPT
Same brand, same engine, different prompt → completely different positioning. Role and sentiment both change dramatically.
The Split Personality Problem
Some brands exhibit what we call "split personalities" — getting assigned completely different roles across prompt types within the same engine. This creates a fundamental identity crisis for AI positioning.
Miro, for instance, appears in four different roles when users ask Perplexity different questions. It's a primary recommendation for whiteboard tools, an alternative for collaboration software, neutral for design tools, and completely absent from project management discussions. That's not a brand with consistent positioning — that's a brand with an identity crisis.
This connects to broader patterns we've observed in how brands struggle with inconsistent AI representation across engines and contexts.
Brand Split Personalities: Same Engine, Multiple Roles
These brands get different roles depending on how users phrase their questions. Identity confusion at scale.
What This Means for GEO Strategy
1. Test all prompt patterns, not just one
If you're only checking "best X" queries, you're seeing 25% of the picture. Users ask questions in many different ways, and each triggers different AI behaviors. Run comprehensive tests across all four prompt archetypes to understand your true AI visibility. Our free brand visibility checker tests multiple prompt patterns automatically.
2. Optimize for prompt-specific behaviors
Gemini rewards decisiveness in "best_X" contexts but Claude focuses on providing balanced alternatives when asked for comparisons. Understanding each engine's prompt-specific personality helps you craft content that aligns with their recommendation patterns.
3. Monitor sentiment across question types
A brand might get enthusiastic treatment in "best" contexts but neutral mentions in "alternatives" contexts. This suggests different content strategies may be needed to capture different user intents. Learn more in our guide to upgrading from alternative to primary recommendations.
4. Address split personality disorders
If your brand appears in different roles across prompt types, you likely have positioning inconsistencies in your source content. AI engines are reflecting conflicting signals about your identity and use cases.
For more strategic insights, check out our comprehensive analysis of whether AI search follows winner-take-all dynamics and our deep dive into which websites AI engines trust most for recommendations.
Frequently Asked Questions
How much can prompt wording affect AI brand recommendations?
Significantly. Our analysis of 4,049 AI responses shows 60% of brands change their role across prompt types, with sentiment swings up to 2.0 points for the same brand.
Which prompt type gets the most primary recommendations?
"Recommend me" prompts slightly edge out "best_X" prompts (37.3% vs 34.7% primary rate). Surprisingly, "alternatives" prompts get the fewest at 25.8%.
Why does asking for alternatives result in fewer primary recommendations?
AI engines interpret "alternatives" literally, focusing on providing options rather than making definitive recommendations. This results in 59.5% alternative mentions.
Which AI engine is most decisive across prompt types?
Gemini maintains the highest decisiveness across all prompt types, with 54.5% primary recommendations for "best_X" prompts and consistent performance across other patterns.
How does sentiment change across different prompt types?
"Best_X" prompts receive the highest sentiment scores (0.62 average), while "alternatives" prompts receive the lowest (0.46). Individual brands can see swings of up to 2.0 points.
What is the Recommend Me Paradox?
Despite asking for recommendations, "recommend me" prompts generate more alternative mentions (54.8%) than primary recommendations (37.3%), suggesting AI engines interpret personal requests as opportunities for comprehensive options.